次のページ 前のページ 「日本語のあれこれ」のトップページ
このテーマの次のページ このテーマの前のページ
万葉集における問題点
このシリーズの第1回の記事で、このシリーズでは「古今集をスタートにする」ことにし、その理由を次のように書きました。
万葉集の方が古いのですが、読みが安定していません。読みに幾通りもの候補が存在します。どれが正しいのか判定が難しいのです。一つの方法として、1音1文字で書かれた歌群があるので、それだけを対象にする、という方法も可能ですが、そうなると、万葉集全体における傾向を考える時に差し支えが出ます。
書棚に「古典文法質問箱」という本が有り、ずいぶん長い間読まずにいたのですが、なんとなく手にとって見ていると、万葉集の一部に対して、それぞれの音(同書では"音節"といっています)の使用頻度を一覧表にしてあるところ(同書 p.52)を見つけました。出現度数が示されています。
次のような説明があります。
私は「万葉集」のうち、一字に漢字一音を当てた表記法を採っている巻、つまり巻五・十四・十五・十七・十八・十九・二十の七巻に使われている万葉仮名(合計四万一千九百四十七)を各音節ごとに勘定し、合計して、私の推定する発音をローマ字で書いた表の下に書き込んでみました。
最初は「1音1文字で書かれた歌群があるので、それだけを対象にする」という方法は「問題があるので採用しない」、と考えたのですが、考えてみると、音の使用頻度を万葉集と古今集とで比較する、という場合には、万葉集の一部だけ抽出しても利用価値はあります。
このシリーズの第8回の記事で「私は少し前に、古今集の字余りについて調査していたことがあり、そのときに仮名書きの古今集のテキストを作っていました」と書きました。今回もこれが使えます。
万葉集についてはこの表を参照し、古今集は自分でカウントし、かな文字の使用頻度を比較使用と思い立ちました。
万葉集(上記の7巻)と古今集では、使用かな文字数の合計が違いますから、出現度数を直接に比較することはできませんので、各集の調査対象の全文字数に対する比率で比較しました。
すると、使用頻度の差がもっとも大きい文字は"ぞ"で、万葉集では甲類4、乙類7の合計11に対して、古今集では274で、出現頻度では万葉集を1とすると古今集は29.2と急増している結果になりました。
万葉集での"ぞ"の出現度数が11だけであるなら、一つ一つチェックするのも簡単です。
そこで万葉集の仮名表記のテキストをダウンロードしてチェックしてみると、何か違うのです。
「古典文法質問箱」に出ていた数値との違いが大きすぎます。
合計の度数は、「古典文法質問箱」では 41,947 ですが、わたしのカウントでは 51,228 になります。
万葉集と古今集との違いの様子を分析することになれば、結局は個別に歌を見なければいけないので、それなら自分で分析した数値を使おう、と方針を転換しました。
万葉集のテキストは 世界の古典つまみ食いのサイトを利用しました。
なお、個別に歌の内容を調査する時には、講談社文庫の万葉集(中西進編)(*2)に準拠しました。
テキスト処理
テキストの処理方法について、自分のための記録という点からも、書き残しておきたいと思います。
いままで試行錯誤的にやってきたので、実際は下記とすこし違った構成です。次回はこうするのが良さそうだ、と感じている内容を示しています。
Excelとテキスト・エディタ(私の場合は"秀丸")を使用します。
やりたいことは、ある文字(または文字列)が含む句のみを歌番号と組み合わせて取り出し、その文字がどのような語句なのかを分類して集計する、というものです。
たとえば、文字"そ"について、どのような語句として使われているかを分類・集計します。たとえば係助詞"こそ"として使われているのが何例あるか、"園(その)"は何例あるか、などという分析です。それによって、二つの歌群の間での差の傾向を知ることができます。○○の使い方が減って、○○の使い方が増えた、というような傾向です。
(1)Excelへテキストの読み込み
元になるテキストで各句がハイフンなどの特殊な文字で区切られている時には、Excelに読み込む時に、区切りコードを指定することにより自動的に一つの句が一つのセルに割り当てられて読み込みができます。それができない時にはテキストエディタで前処理をします。
1行に1首とし、一つの句を一つのセルに対応させます。短歌なら五つのセルになり、長歌ならそれより多くのセルの並びになります。今回調査したなかでもっとも長い歌は巻17の4011番歌で114句(637文字)でした。
巻数と歌番号は重要です。元のテキストにある形態からコピーしておきます。巻数と歌番号は別々のセルに入るようにした方が融通が利いて便利でしょう。
(2)文字数カウント
左端に3列の空きの行を作り、各歌の全句を統合したテキスト、その文字数と句数を入れます。全句テキストは最も多いセルの歌について文字列の連結("&")で簡単に作れます。文字数はその文字数を関数"LEN"で求めます。句数はもっとも句数が多いものを基準に、その中の空白セルを引いて求めることができます。
(3)短歌のみを選別
今回は短歌のみを処理対象としました。理由は後述します。そのために左端に3列の空きの行を作り、各歌の句数が 6 以上のものには"0"、それ以外は"1"を入れて、その行の内容でソートすると、"0"の歌(短歌より長い歌)が上の方に集まりますから、まとめて削除します。
(4)指定文字列が含まれる句の選択
各句(短歌のみなので全5句)の右側に6行の空きを作ります。5行(X1,X2,X3,X4,X5とします)は各句の中に指定文字があれば当該句のテキストをコピーし、なければ空白セルのままとします。残りの1行(Zとします)はX1~X5の行の内容を文字列連結した内容を格納します。
各句の中に指定文字があるかどうかの判定ですが、まだよい方法が見つかっていません。今のところは、各句のセル内テキストで指定文字をゼロ文字で置き換え(SUBSTITUTE関数を利用する)、その結果の文字数(LEN関数)と元々のセル内文字数が等しければ指定文字はなし、等しくなければ指定文字がある、と判断します。
記述する内容はたとえば "=IF(LEN($I6)-LEN(SUBSTITUTE($I6,O$4,""))>0,$I6,"")" のようになります。ある句が"I6"のセルに格納されていて、SUBSTITUTE関数はそのセルの内容をチェックして指定文字列(O$4のセルに格納されている)を探してそれを3番目の引数(ここではゼロ文字)で置き換えます。「ゼロ文字で置き換える」ということは「削除する」ことと同じです。指定文字列がない場合にはSUBSTITUTE関数は指定セルの内容をそのまま返します。指定文字列が一つの句に複数個含まれている場合にはすべてがゼロ文字に置き換えられます。
SUBSTITUTE関数を実行させたときに文字数が変化した場合には、その句には指定文字列が含まれていたことになるので、その句の内容を当該箇所に埋めます。
(5)指定文字列が含まれる句における使われ方の分類
上記(4)で選別されたセルについてひとつひとつ見ていき、指定文字列の使われ方を分類します。これは人による作業です。上記した列Zの隣に列Yを挿入し、分類名を書き込みます。たとえば"こそ"、"その(園)"、"な-そ"などというように、自分でわかりやすい表記にします。
この表記は、後で統計処理する時に重要な情報です。重要なことは、同じ内容について異なる表記をしない、ということです。たとえば"こそ"について、ある時には"こそ(係助詞)"と書き、別の所では"係助詞(こと)"と書くと、この二つは別の項目として分類されてしまい、後で手作業で修正することになります。
経験的にいえば、まずその語句を仮名表記にして、続けてカッコ内に説明を追加するのが良いように思われます。そうすれば、たとえば"こそ(係助詞)"と"係助詞(こと)"のような混乱を避けやすくなります。また"その(園)"と"その(苑)"は連続して表示され、わかりやすくなります。元のテキストで"かな表記"か"漢字表記"か、あるいは"どの漢字を使うか"ということは、元になるテキストによって異なる(一つのテキストでも時には複数の表記がなされることがあります)ことが多いので、その違い(あるいは違っているが同じことである、ということ)が気づきやすくなります。
実例を下に示します。
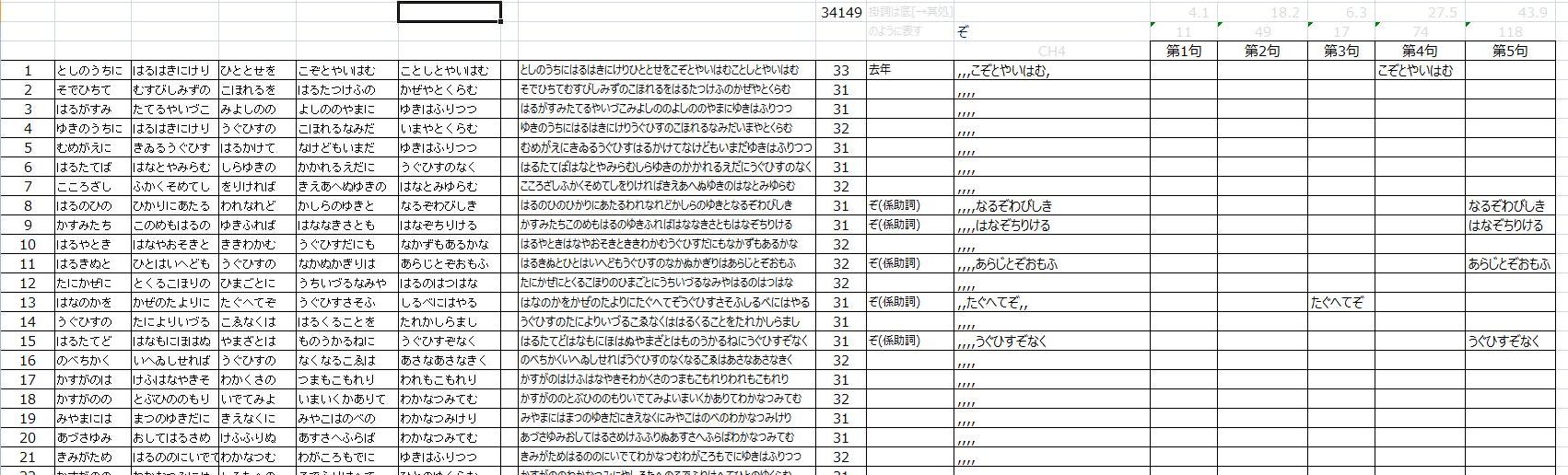
図1 指定文字列を各歌の各句で検索した例
各列の内容は、左から、歌番号、第1句~第5句、空白列、全句、全句の文字数、検出文字列の説明、検出文字列を含む全句、検出文字列を含む各句の内容です。"検出文字列の説明"の上部に検出文字列を格納するセル(上の例では"ぞ"と表示)をもうけてあります。
(本題と直接関係のない項目は薄い色にしてあります。)
(6)統計処理
たとえば"そ"という文字について、その使われ方を統計処理したい、ということがあります。"こそ(係助詞)"、"その(園)"はそれぞれ何例あるか、あるいはもっと一般的に、ある歌集で"そ"の文字の使われ方を分類して、使用パターンの頻度が高い順にトップ10を抽出したい、というようなケースです。
上記の列Yを使用します。その内容をコピーしてテキストエディタに貼り付けます。各行には、各歌の中で指定文字列が使われた句の内容が表示されています。使用されていない歌の部分は単に改行文字だけが入ります。
テキストエディタを使って以下のような手順で進めます
(a)ムダな改行の削除…途中にある改行だけの行を削除します。
(b)一つの句に指定文字列が複数個ある時、1行に書かれているので、別の行にします。たとえば、「われなれど」という句で、"れ"を検索すると、"われ(我)"と"なれ(なりの已然形)"の二つが検出されるので、"われ(我)・なれ(なりの已然形)"などと書いていきます。"・"は検出語句が一つの句の中に2個以上あった時に使うということにしています。このとき、"・"を"改行コード"と置き換えて別の行にします。テキストエディタではこのような文字の置き換えが簡単な操作で行うことができます。
(c)上の結果をExcelに貼り付けて、1列のデータ(列P)として、データの並び替え(ソート)をします。その結果、同じ項目が連続して並べられます。
(d)その隣に1行挿入して(列Q)、同一項目カウンタを表示させます。同一項目カウンタは"1"から始まり、同じ項目が続いていれば"+1"ずつしていき、項目が変わると"1"にリセットします。
(e)一つの項目がいくつ並んでいるかは、次のようにして検出します。行Qの隣に行Rを挿入します。行Rは行Qのセルが1のとき、その直前のセルに行Qの同じ行の内容をコピーします。その結果、行Rには、各項目が何個並んでいるかを示す数値が飛び飛びに表示されます。列Rの値で列P~Rをソートすると、出現頻度順に各項目が並べられます。
例を一つ示します。"そ"、"ぞ"について、古今集(短歌のみ)と万葉集(前述の7巻の短歌のみ)を調査したもので、それぞれの出現頻度トップ10をまとめたものです。
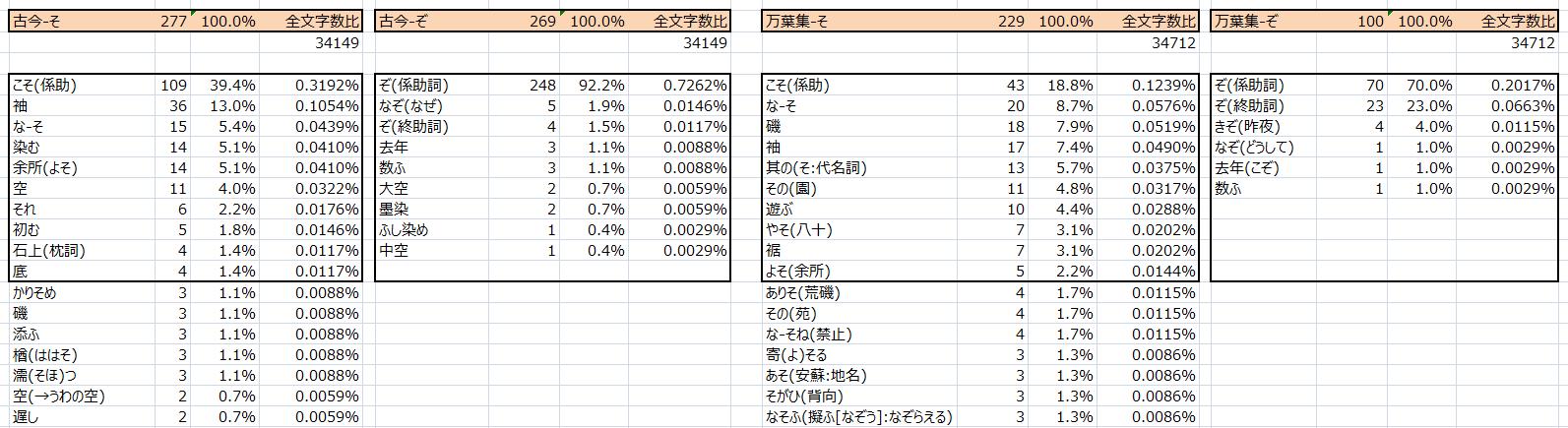
図2 文字の出現頻度ランキングの検出例
このようなやり方はいろいろと応用が聞きます。
たとえば、"あ、い、う、え、お、か、き、…"の各文字の使用頻度を調査するとします。
いままで書いてきた方法で一つの文字の使われ方をチェックできますが、単純に文字そのものであれば、一気にチェックすることができます。
各歌の各句を並べた隣に、"あ、い、う、え、お、か、き、…"という[あ~を]の50文字、濁音の[がざだば行]の20文字の合計70文字に対応する欄をもうけます。
一行上のところに[あ~を]の50文字、濁音の[がざだば行]の20文字を書いておきます。
最初では、第1首の全句の欄で"あ"を検索し、その個数を記入します。これを"い、う、え、お、か、き、…"について続けていきます。
上記を全歌について繰り返します。
古今集について実施したイメージは次の図3のようになります。
"あ"~"ぼ"までの70文字を並べてそれぞれの出現回数をカウントしています。右端には、図1で説明した部分が現れています。この表は左右に長いものになるので、ここでは一部の列を非表示にしています。
参考までに、1番歌に対する"あ"の出現回数をチェックする式が左上に表示してあります。
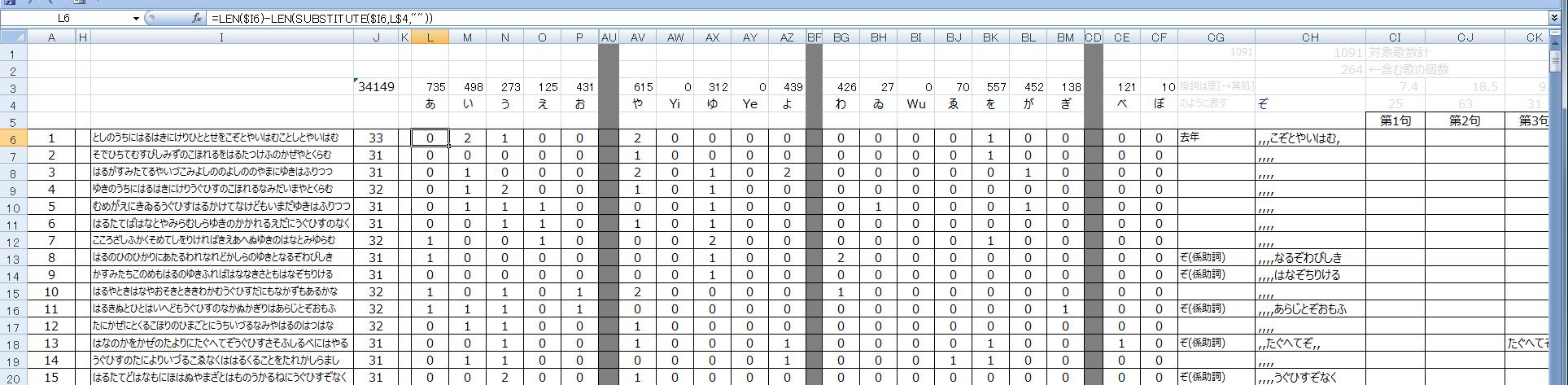
図3 全かなの出現頻度検出結果の例
参考
(*1) 古典文法質問箱 大野晋 角川ソフィア文庫 角川学芸出版 平成20年8月
(*2) 万葉集 全訳注原文付(一)~(四)、別巻 中西進編 講談社 2009年6月